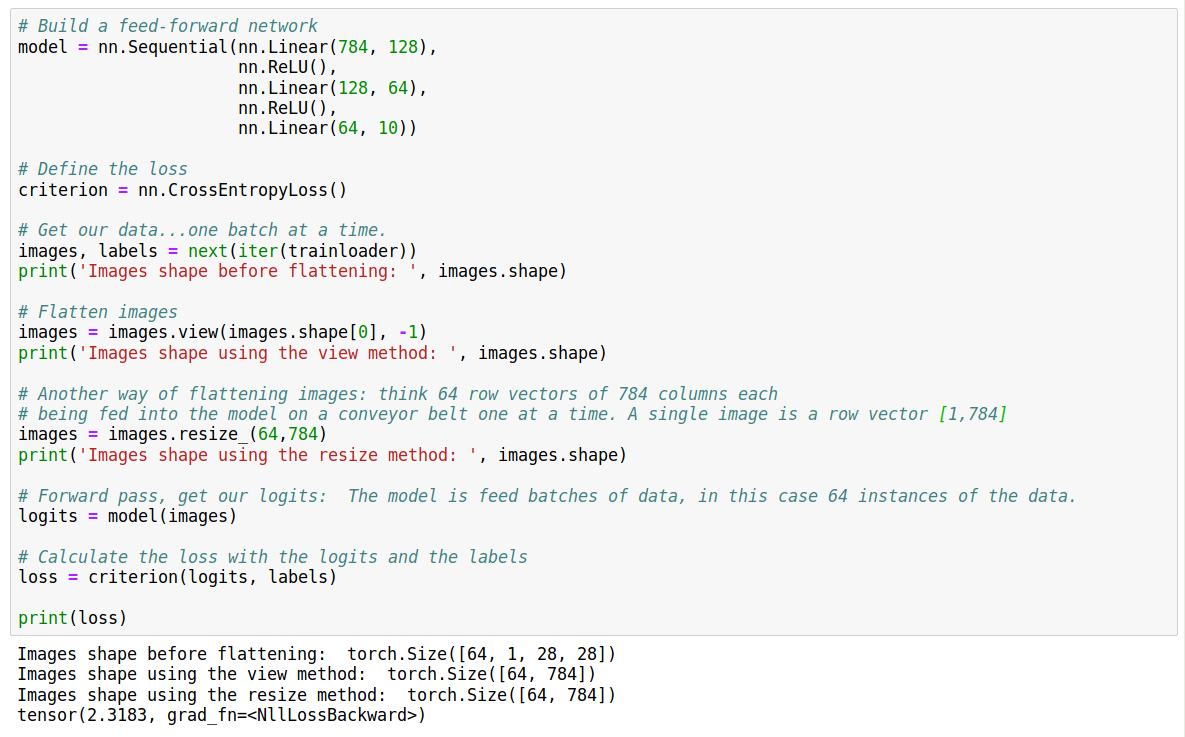
So what is this “data flattening” business? The short answer is that the input to our neural network is a column vector of dimension n X 1 therefore for the vector dot product to make sense each time we feed one image means we need an input array of dimension m X n. In our examples m = 64 (batches) and n = 784 (pixels) since the original dimensions of each image is 28 X 28 = 784.